Abstrarct
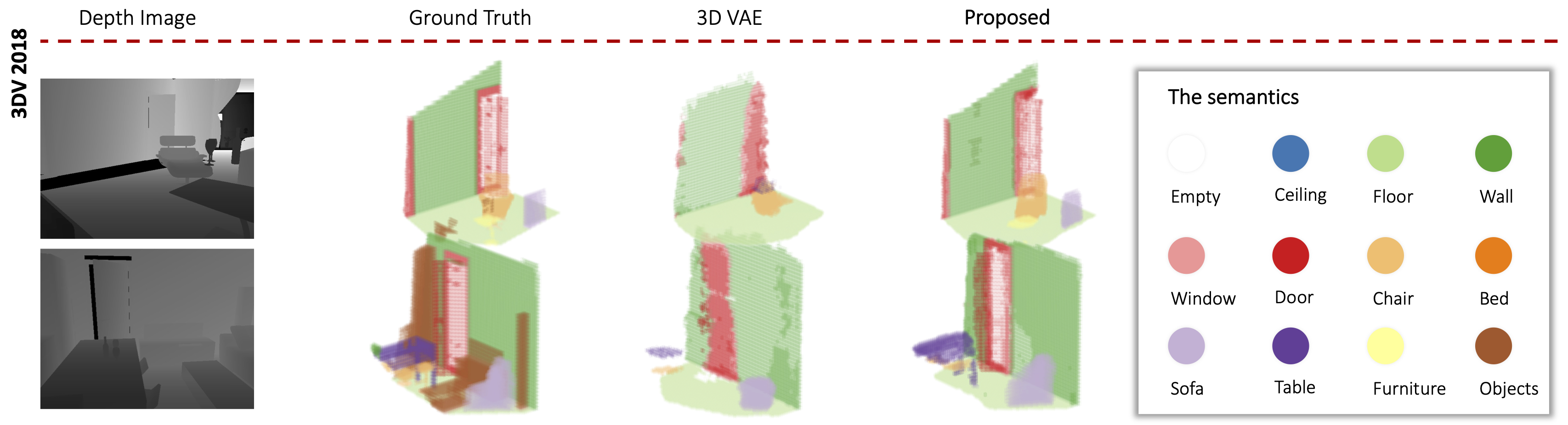
We propose a method to reconstruct, complete and semantically label a 3D scene from a single input depth image. We improve the accuracy of the regressed semantic 3D maps by a novel architecture based on adversarial learning. In particular, we suggest using multiple adversarial loss terms that not only enforce realistic outputs with respect to the ground truth, but also an effective embedding of the internal features. This is done by correlating the latent features of the encoder working on partial 2.5D data with the latent features extracted from a variational 3D autoencoder trained to reconstruct the complete semantic scene. In addition, differently from other approaches that operate entirely through 3D convolutions, at test time we retain the original 2.5D structure of the input during downsampling to improve the effectiveness of the internal representation of our model. We test our approach on the main benchmark datasets for semantic scene completion to qualitatively and quantitatively assess the effectiveness of our proposal.
Cite
If you find this work useful in your research, please cite:
@inproceedings{wang2018adversarial,
title={Adversarial semantic scene completion from a single depth image},
author={Wang, Yida and Tan, David Joseph and Navab, Nassir and Tombari, Federico},
booktitle={2018 International Conference on 3D Vision (3DV)},
pages={426--434},
year={2018},
organization={IEEE}
}