Home
Archive
Categories
Tags
Home
Posts
An Encoder-Decoder Network for Point Cloud Completion (SoftPool++)
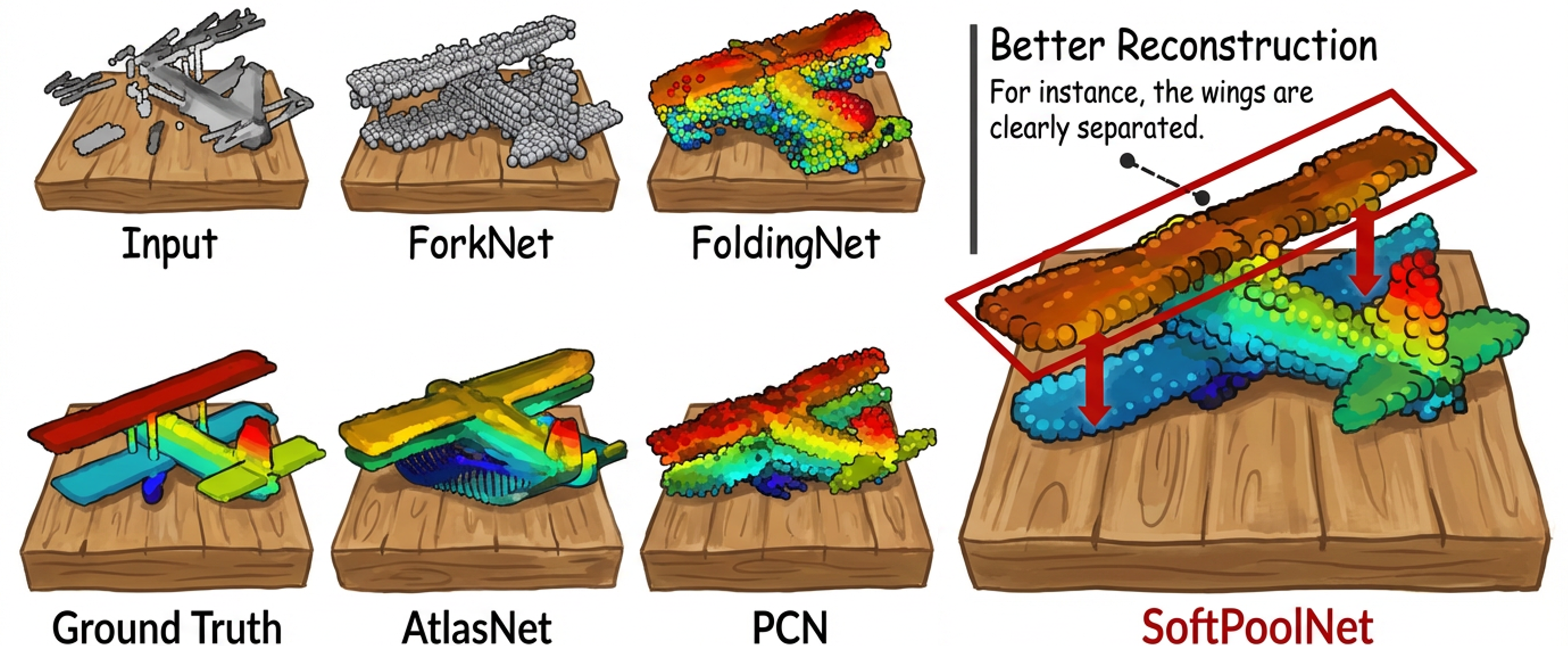
Shape Descriptor for Point Cloud Completion and Classification (SoftPoolNet)
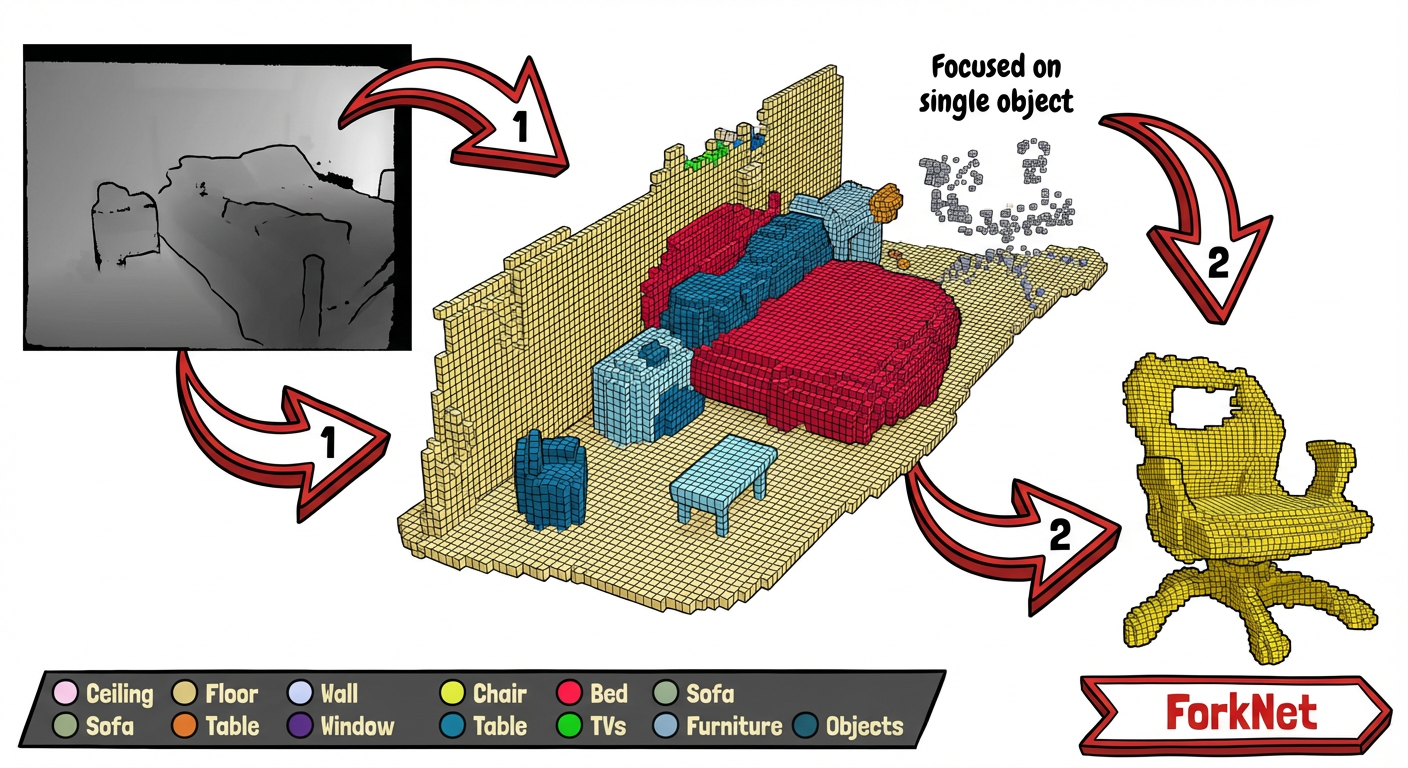
Multi-Branch Volumetric Semantic Completion From a Single Depth Image (ForkNet)
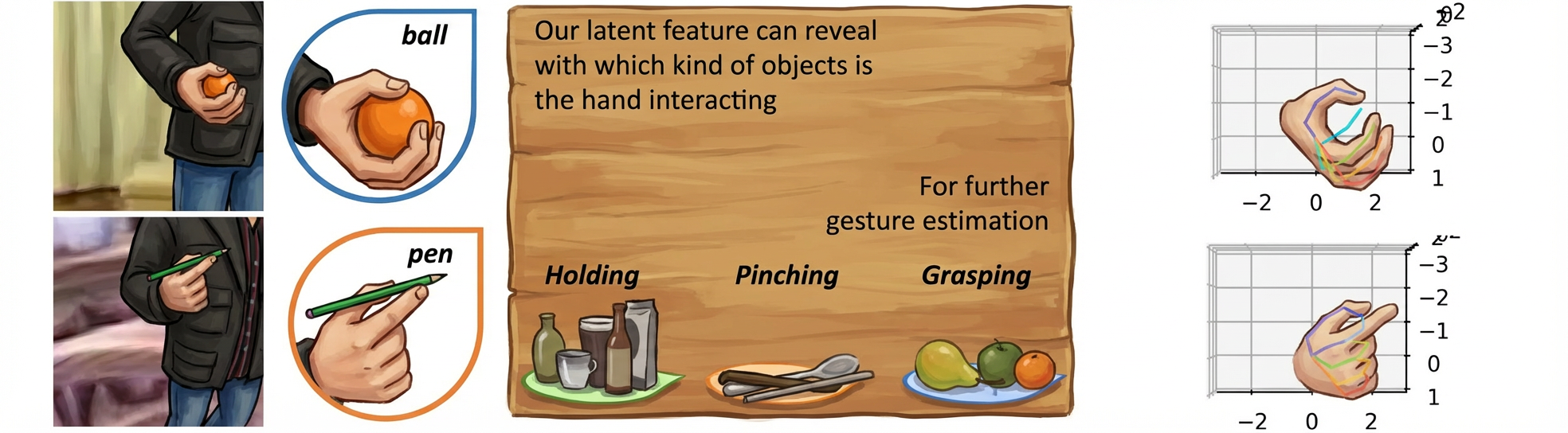
Variational Object-aware 3D Hand Pose from a Single RGB Image
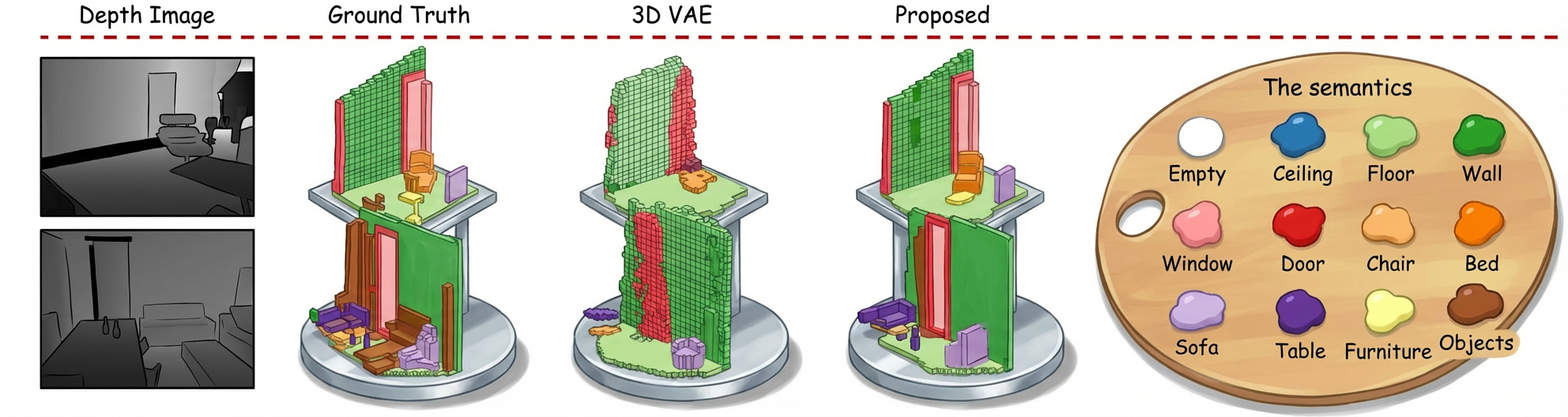
Adversarial Semantic Scene Completion from a Single Depth Image
Generative Model with Coordinate Metric Learning for Object Recognition Based on 3D Models
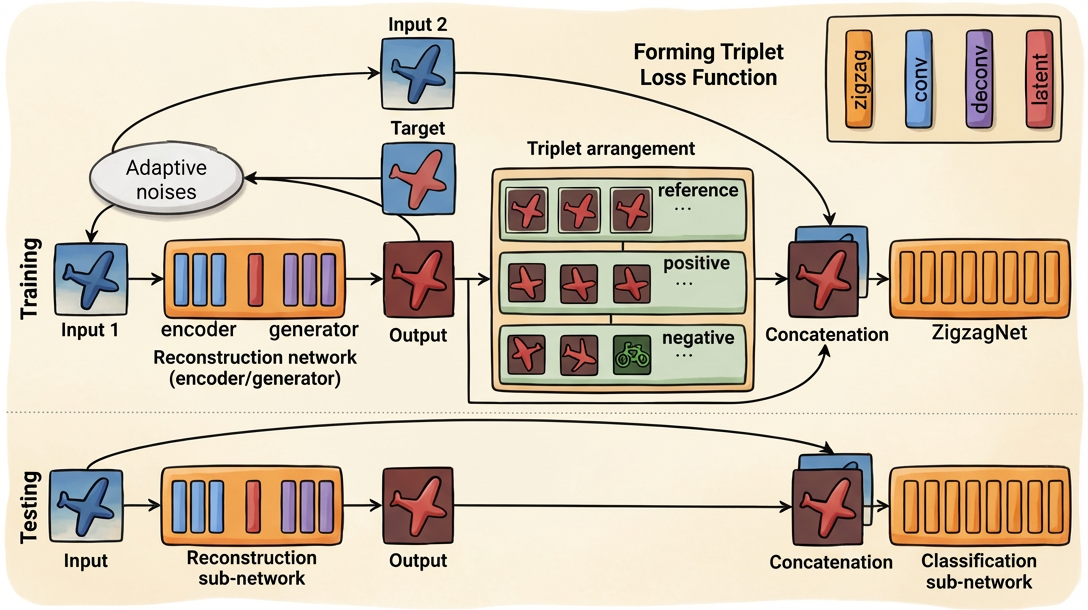
Efficient deep learning for real object recognition based on 3D models (ZigzagNet)
Self-restraint Object Recognition by Model Based CNN Learning