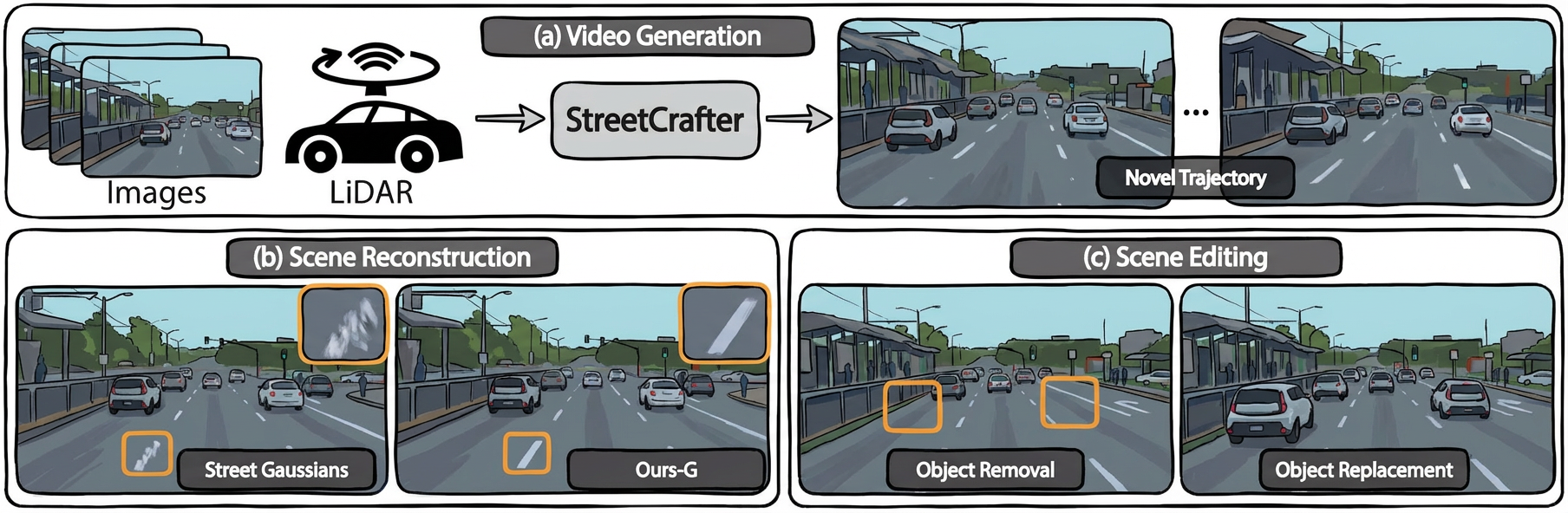
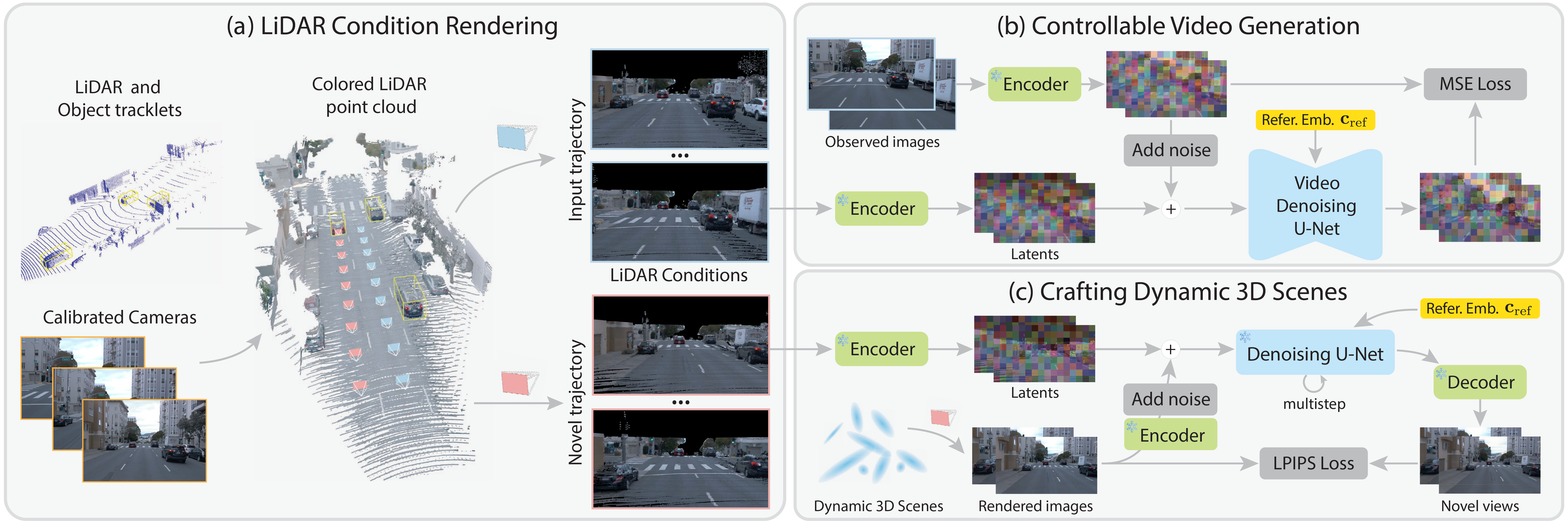
This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensors data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR condition allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open and PandaSet datasets demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
Methodology
Architectures
Qualitatives

Cite
If you find this work useful in your research, please cite:
@inproceedings{yan2024streetcrafter,
title={StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models},
author={Yan, Yunzhi and Xu, Zhen and Lin, Haotong and Jin, Haian and Guo, Haoyu and Wang, Yida and Zhan, Kun and Lang, Xianpeng and Bao, Hujun and Zhou, Xiaowei and Peng, Sida},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025},
}