Re-direct to the full PAPER and PROJECT PAGE
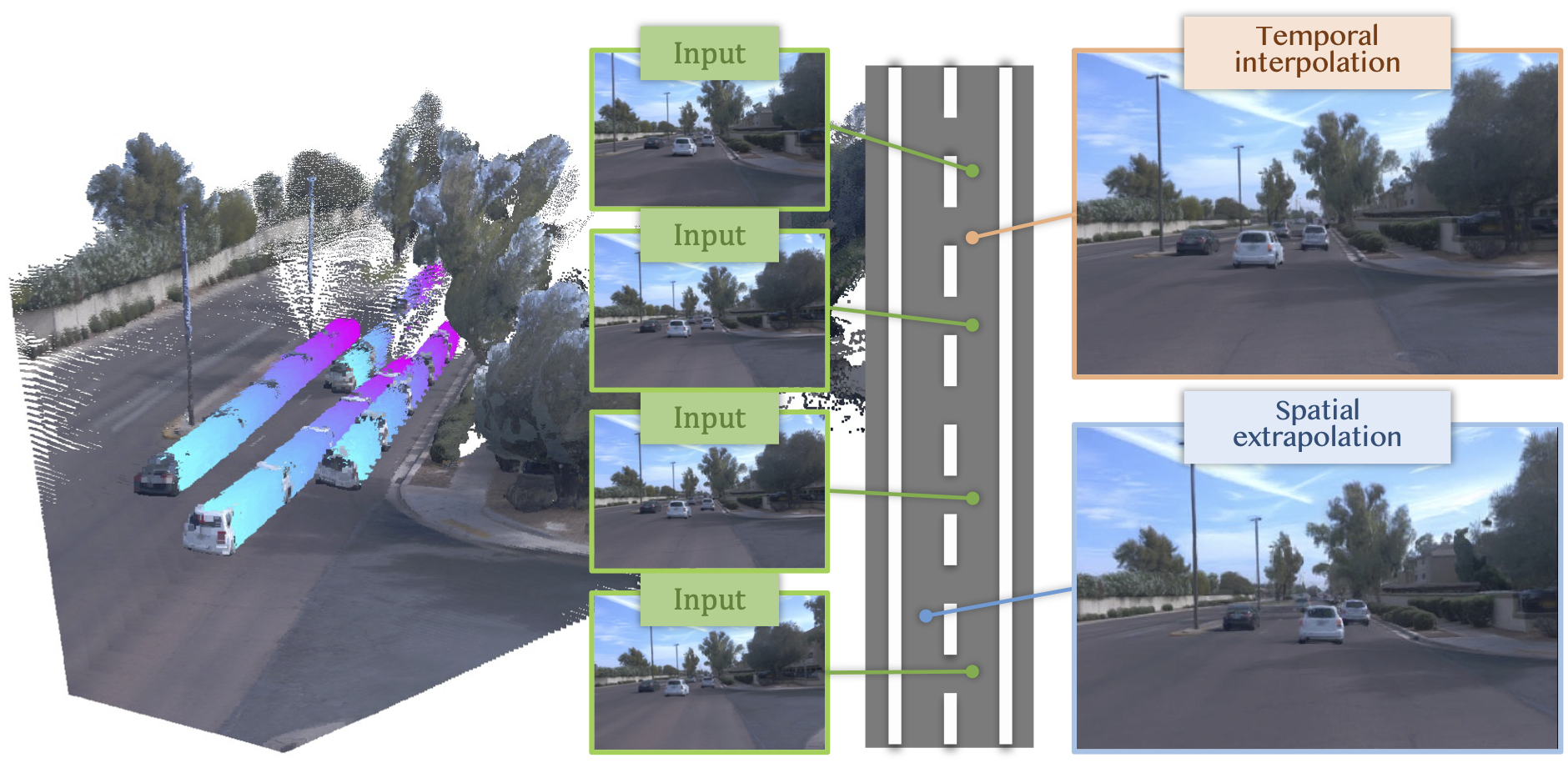
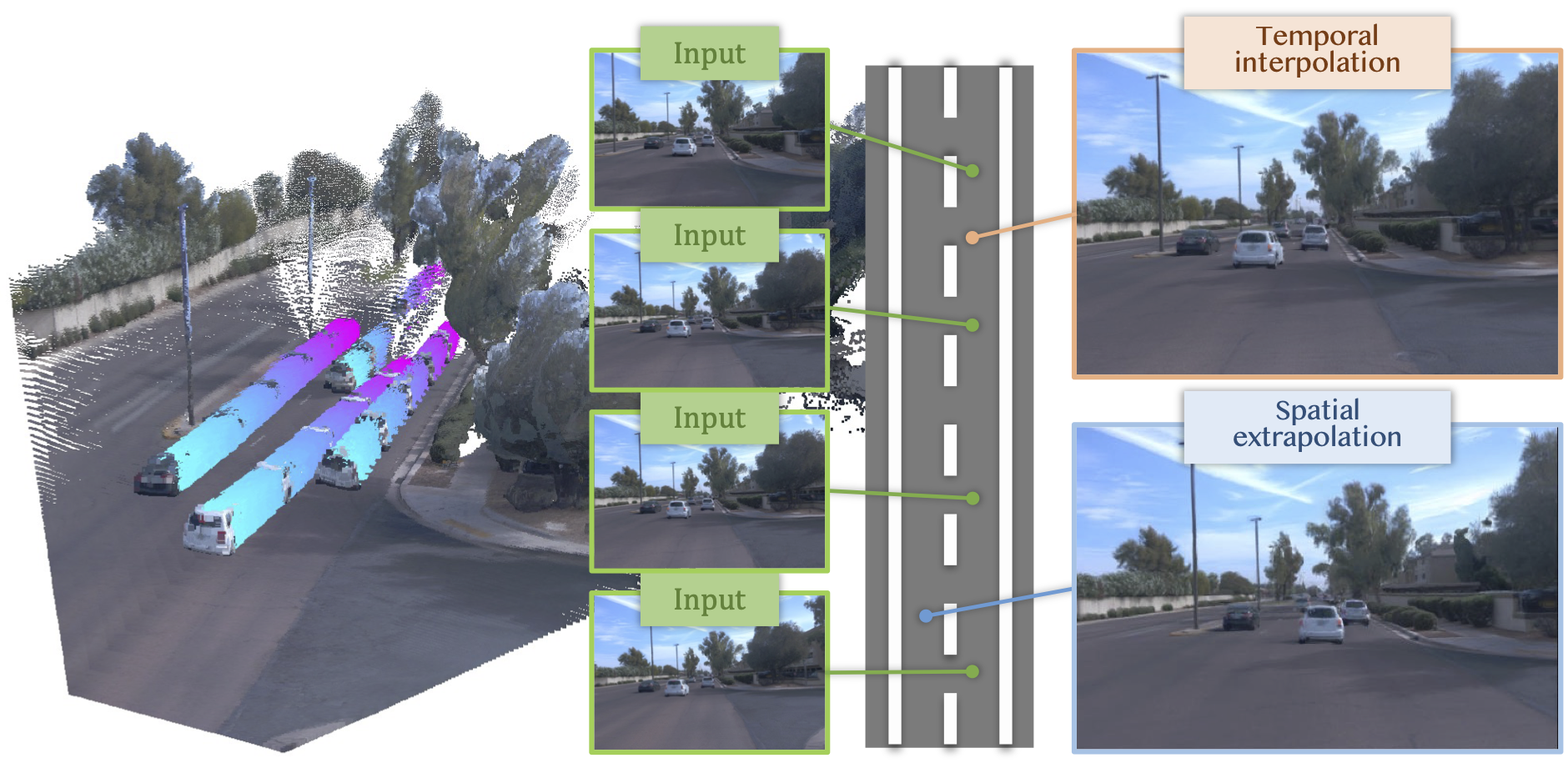
We present StreetForward, a pose-free and tracker-free feedforward framework for dynamic street reconstruction. Building upon alternating attention, it introduces a temporal mask attention module that captures dynamic motion from image sequences and produces motion-aware latent representations. Static content and dynamic instances are represented uniformly with 3D Gaussian Splatting and optimized jointly through cross-frame rendering with spatio-temporal consistency, enabling high-fidelity novel-view synthesis at new poses and times while also estimating per-pixel velocities.
Methodology
Pipeline
The input video is encoded into per-frame patch features and processed by alternating global and frame attention to aggregate temporal information. A causal masked attention module then forms motion-aware features that estimate motion and dynamic masks, and the final 4D scene is obtained by combining static Gaussians with propagated dynamic Gaussians.
Qualitative Comparison
Spatial Extrapolation
Temporal Interpolation
More Results
Real application For mountain areas
A real application example for mountain areas.
Cite
If you find this work useful in your research, please cite:
@article{yu2026streetforward,
title={StreetForward: Perceiving Dynamic Street with Feedforward Causal Attention},
author={Yu, Zhongrui and Wang, Zhao and Xie, Yijia and Wang, Yida and Zhang, Xueyang and Zhan, Yifei and Zhan, Kun},
journal={arXiv preprint arXiv:2603.19552},
year={2026}
}